Imagine that you’re building an outstanding mobile application that needs server side support for certain features, like syncing user data or showing posts from other users. Your app is useful and full of animations. However, sometimes it looks laggy while it’s performing server requests; maybe the server is slow, or it often responds with errors. Of course, most users don’t understand the real reason behind lagging – next time when they see a “network error” message, they remove your app, give you a ★☆☆☆☆ rating and write negative review.
Special thanks to @tanzor for his hard work on investigating server performance.
You can solve this kind of problem in two ways: either using optimistic models in your app and avoid showing a “network error” message, or improving your Node.js server performance. The following advice is based on our experience of improving backend servers for some of our mobile apps.
If you are an experienced backend developer, the following tips may be too obvious for you, but you may still find some inspiration!
Given Infrastructure
Imagine an Ubuntu server, full of Docker containers: one container is Node.js web-server, another one is NoSQL database, the last one is nginx “to rule them all”. A typical MEAN-ish stack.
This server is used for serving app requests, doing some business logic, reading and writing data to a database, sending push notifications, etc. Not HighLoad, not BigData. Jus a modest REST-API server.
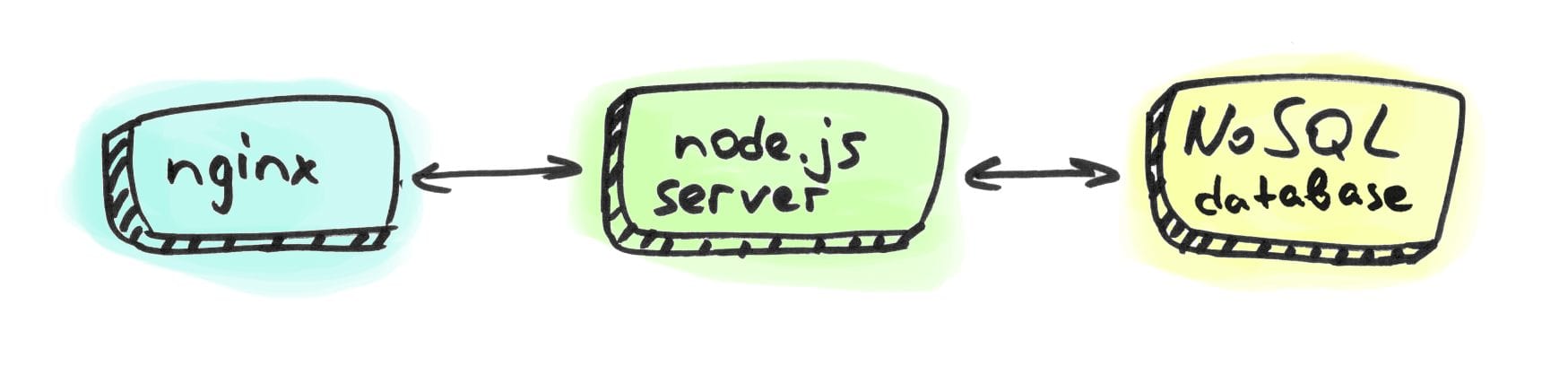
We can always try to improve server performance no matter how simple the server structure and business logic are.
What to improve
Of course, you can’t blindly change something, hoping that this will lead to improvement. Measure the change!
We use different monitoring tools to collect server metrics. The most important metric for us is response time, which describes how fast the server responds to app requests. Basically, everything affects the response time, from outdated hardware to inefficient code.
Optimizing database
We believe that databases are the core of REST-API servers and their performance affects the whole server performance.
The one and only basic database theory sounds like this:
We always tend to write data irresponsibly, carelessly, thinking we can just let it hide in the background, but when it comes to reading data, you don't just need the data itself, but also performance and operations on data.
Performance and ease of operations on data is directly proportional to the amount of thinking time spent while recording the data. Understanding this fundamental principle allows you to predict and affect future database performance.
Upgrading to MongoRocks
One huge step forward for us was upgrading the storage engine for MongoDB from WiredTiger to RocksDB. We used MongoRocks to connect MongoDB to RocksDB engine. Parse folks recommend using MongoRocks for Parse Server backends, but it may suit your backend too, please follow their guide for more details.
RocksDB has been used with fast storage to support IO-bound, in-memory and write-once workloads. In addition RocksDB is fully open sourced and flexible to allow for innovation. We used Percona Server as our storage provider.

The migration was simple:
- Install and run Docker container of Percona Server for RocksDB, link the database to the custom port that differs from current MongoDB’s port.
- Create a backup of current database.
- Deploy a backup to RocksDB, verify data.
- Change RockDB’s port from custom to the original one.
- Enjoy!
Updating database indexes
Any indexing strategy is based on two things: how the data will be read and the advantages/disadvantages of each type of indexing. Of course, the need to keep indexes up-to-date is a known rule.
When we are adding new user features to the mobile app, we need to update the database model accordingly. It means that we may need to update indexes too. However, users don’t update their apps quickly: along with the new features you also need to support old ones, and thus you get old requests and old indexes.
Even when most users have updated their apps to the new versions, we tend to forget to remove old indexes, which leads to slower performance. Eventually, we created a configuration file for storing indexes and a script for updating them efficiently.

Removing debug logs
Although storing debug logs in the primary database doesn’t sound like a good idea at all, some developers tend to put everything in one bucket. Server performance depends on database performance, but when the database is full of debug data, transactions take a longer time to run.
It’s important to distinguish user-generated data from service data (OLTP vs OLAP), and to handle them with the appropriate instruments. If you need to store and analyze a lot of logs, take a look on the ELK stack, or create a separate database for tracking user activities.
Furthermore, cleaning old and unneeded logs helps to keep your database healthy.
Removing old files, cleaning up a database
No need to explain: some data has an expiration time, so it can be removed after that. If you don’t remove old data, sooner or later your collections will look like a dump. No one wants to search for valuable data inside a dump.
We don’t remove data manually, instead we’ve created cron jobs to remove it once a week.
(The tricky question is: how to understand what data can be removed without consequences. It totally depends on your product and the logic behind it.)
[custom_form form="form-inline-subscribe" topic="Development"]
Optimizing requests
Grouping requests and minimizing transferred data
Users prefer simple interfaces, especially when they need to fill in a lot of data. Splitting large forms into several simple steps improves UX and makes users happy, but sending server requests on each screen is overloading the server.
Instead of sending multiple requests, the app should remember the user’s choice and store it until the user completes the form. After that the app sends all input data in a single request. Of course, this strategy doesn’t suit every situation, but consider it next time.
A similar idea is request cancellation. Let’s imagine that the user presses the ‘like’ button multiple times; instead of sending a ‘like’ request for every tap, an application should cancel insignificant requests and send the resulting value only. This approach requires more time and wise thinking, but it’s easy to implement: you can read more about it in the Optimistic Models Part 2 post.
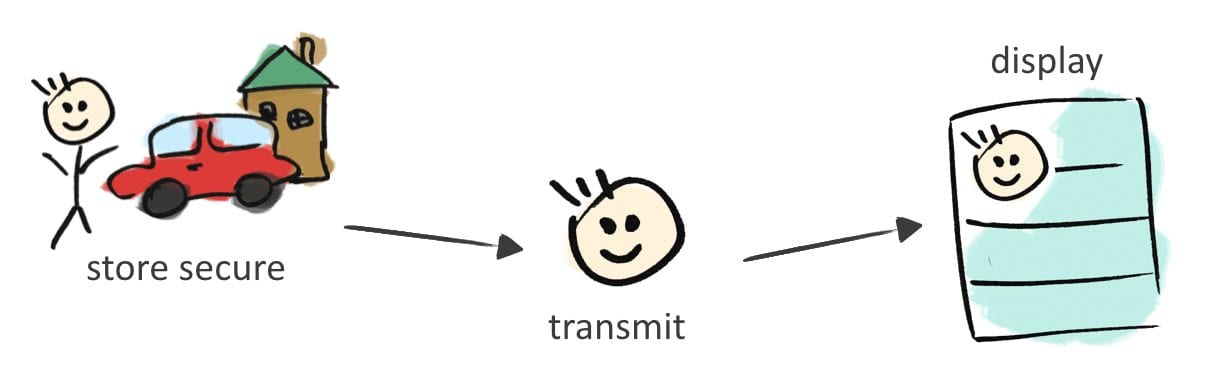
From the other side, the server should send only the required data. Compartmentalization is the idea of limiting access to information only to those who need it now. For example, if the application needs to display the user’s photo and name, the server should send the minimum required information, instead of sending the whole user record stored in the server database.
Results
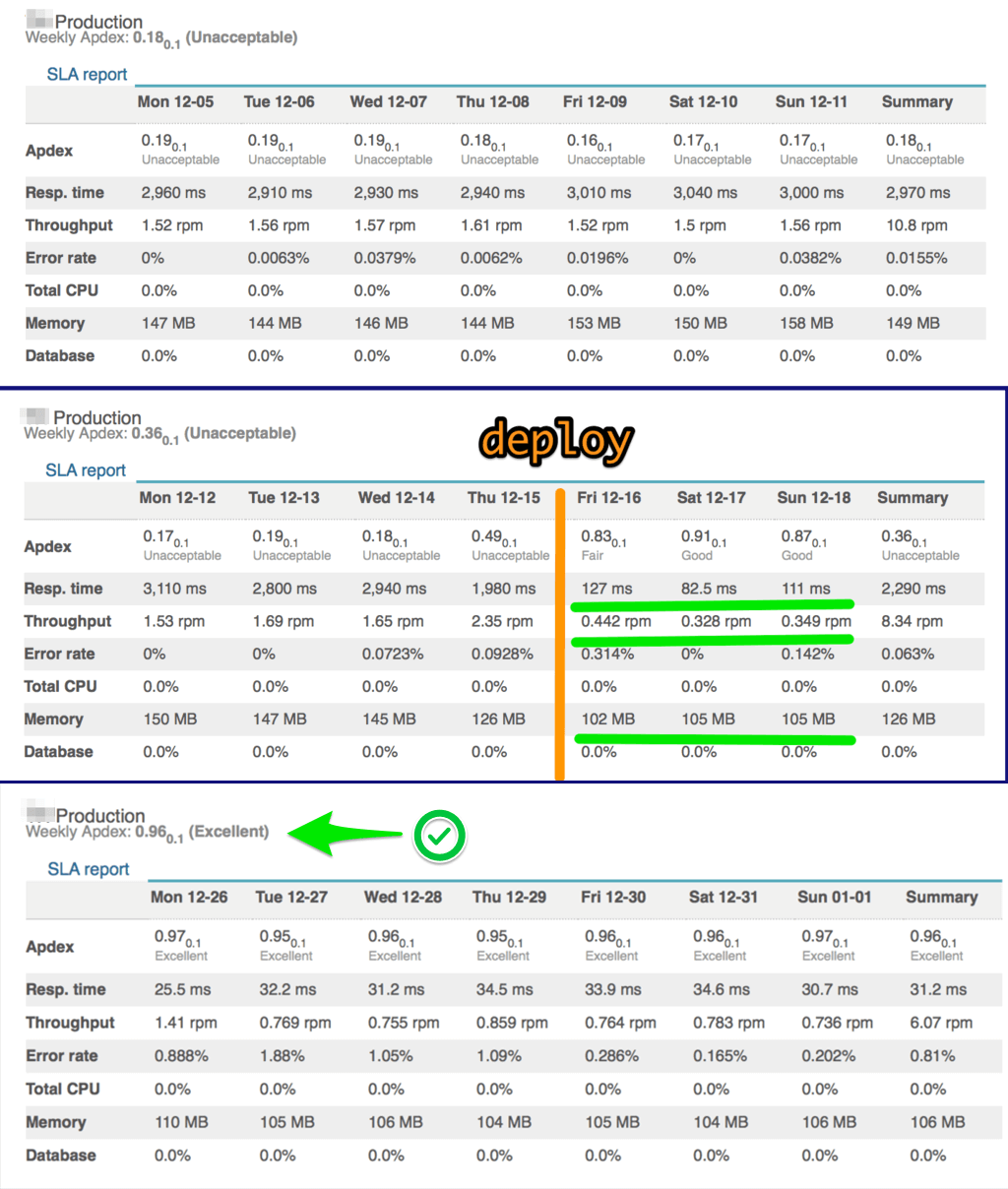
Using the techniques described above we decreased response time by 100 and improved the Apdex Index from “unacceptable” to “excellent” (according to the NewRelic monitoring).
Of course, those techniques may not suit for your backend, however they are based on the simple ideas:
- manage data carefully;
- do not store unneeded data;
- minimize traffic.
Let us know what techniques do you use to keep your servers in shape!